
Stable Audio: Fast Timing-Conditioned Latent Audio Diffusion
Visit stableaudio.com
Introduction
The introduction of diffusion-based generative models has revolutionized the field of generative AI over the last few years, leading to rapid improvements in the quality and controllability of generated images, video, and audio. Diffusion models working in the latent encoding space of a pre-trained autoencoder, termed “latent diffusion models”, provide significant speed improvements to the training and inference of diffusion models.
One of the main issues with generating audio using diffusion models is that diffusion models are usually trained to generate a fixed-size output. For example, an audio diffusion model might be trained on 30-second audio clips, and will only be able to generate audio in 30-second chunks. This is an issue when training on and trying to generate audio of greatly varying lengths, as is the case when generating full songs.
Audio diffusion models tend to be trained on randomly cropped chunks of audio from longer audio files, cropped or padded to fit the diffusion model’s training length. In the case of music, this causes the model to tend to generate arbitrary sections of a song, which may start or end in the middle of a musical phrase.
We introduce Stable Audio, a latent diffusion model architecture for audio conditioned on text metadata as well as audio file duration and start time, allowing for control over the content and length of the generated audio. This additional timing conditioning allows us to generate audio of a specified length up to the training window size.
Working with a heavily downsampled latent representation of audio allows for much faster inference times compared to raw audio. Using the latest advancements in diffusion sampling techniques, our flagship Stable Audio model is able to render 95 seconds of stereo audio at a 44.1 kHz sample rate in less than one second on an NVIDIA A100 GPU.
Audio Samples
Music
Instruments
Sound Effects
Technical details
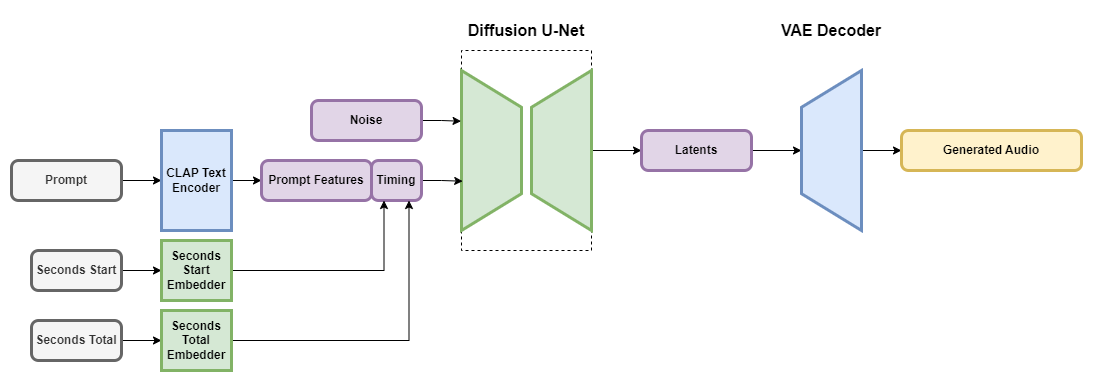
The Stable Audio models are latent diffusion models consisting of a few different parts, similar to Stable Diffusion: A variational autoencoder (VAE), a text encoder, and a U-Net-based conditioned diffusion model.
The VAE compresses stereo audio into a data-compressed, noise-resistant, and invertible lossy latent encoding that allows for faster generation and training than working with the raw audio samples themselves. We use a fully-convolutional architecture based on the Descript Audio Codec encoder and decoder architectures to allow for arbitrary-length audio encoding and decoding, and high-fidelity outputs.
To condition the model on text prompts, we use the frozen text encoder of a CLAP model trained from scratch on our dataset. The use of a CLAP model allows the text features to contain some information about the relationships between words and sounds. We use the text features from the penultimate layer of the CLAP text encoder to obtain an informative representation of the tokenized input text. These text features are provided to the diffusion U-Net through cross-attention layers.
For the timing embeddings, we calculate two properties during training time when gathering a chunk of audio from our training data: the second from which the chunk starts (termed “seconds_start”) and the overall number of seconds in the original audio file (termed “seconds_total”). For example, if we take a 30-second chunk from an 80-second audio file, with the chunk starting at 0:14, then “seconds_start” is 14, and “seconds_total” is 80. These second values are translated into per-second discrete learned embeddings and concatenated with the prompt tokens before being passed into the U-Net’s cross-attention layers. During inference, these same values are provided to the model as conditioning, allowing the user to specify the overall length of the output audio.
The diffusion model for Stable Audio is a 907M parameter U-Net based on the model used in Moûsai. It uses a combination of residual layers, self-attention layers, and cross-attention layers to denoise the input conditioned on text and timing embeddings. Memory-efficient implementations of attention were added to the U-Net to allow the model to scale more efficiently to longer sequence lengths.
Dataset
To train our flagship Stable Audio model, we used a dataset consisting of over 800,000 audio files containing music, sound effects, and single-instrument stems, as well as corresponding text metadata, provided through a deal with stock music provider AudioSparx. This dataset adds up to over 19,500 hours of audio.
Future work and open models
Stable Audio represents the cutting-edge audio generation research by Stability AI’s generative audio research lab, Harmonai. We continue to improve our model architectures, datasets, and training procedures to improve output quality, controllability, inference speed, and output length.
Keep an eye out for upcoming releases from Harmonai, including open-source models based on Stable Audio and training code to allow you to train your audio generation models.