
Stable Diffusion 2.0 Release

We are pleased to announce the open-source release of Stable Diffusion Version 2.
The original Stable Diffusion V1 led by CompVis changed the nature of open source AI models and spawned hundreds of other models and innovations worldwide. It had one of the fastest climbs to 10K GitHub stars of any software, rocketing through 33K stars in less than two months.
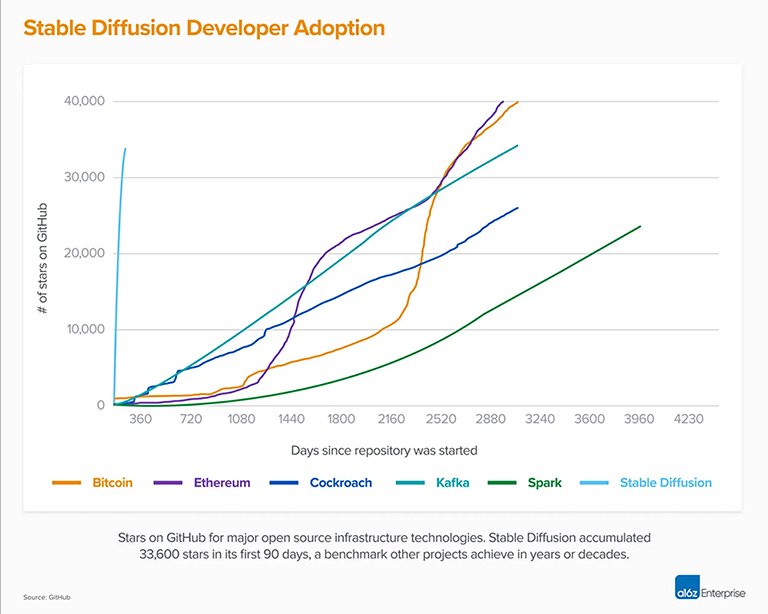
Source: A16z and Github
The dynamic team of Robin Rombach (Stability AI) and Patrick Esser (Runway ML) from the CompVis Group at LMU Munich, headed by Prof. Dr. Björn Ommer, led the original Stable Diffusion V1 release. They built on their prior work in the lab with Latent Diffusion Models and got critical support from LAION and Eleuther AI. In our earlier blog post, you can read more about the original Stable Diffusion V1 release. Robin is now leading the effort with Katherine Crowson at Stability AI to create the next generation of media models with our broader team.
Stable Diffusion 2.0 delivers several big improvements and features versus the original V1 release, so let’s dive in and take a look at them.

New Text-to-Image Diffusion Models
The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases. The text-to-image models in this release can generate images with default resolutions of 512x512 pixels and 768x768 pixels.
These models are trained on an aesthetic subset of the LAION-5B dataset created by the DeepFloyd team at Stability AI, which is then further filtered to remove adult content using LAION’s NSFW filter.

Examples of images produced using Stable Diffusion 2.0, at 768x768 image resolution.
Super-resolution Upscaler Diffusion Models
Stable Diffusion 2.0 also includes an Upscaler Diffusion model that enhances the resolution of images by a factor of 4. Below is an example of our model upscaling a low-resolution generated image (128x128) into a higher-resolution image (512x512). Combined with our text-to-image models, Stable Diffusion 2.0 can generate images with resolutions of 2048x2048–or even higher.

Left: 128x128 low-resolution image. Right: 512x512 resolution image produced by Upscaler.
Depth-to-Image Diffusion Model
Our new depth-guided stable diffusion model, called depth2img, extends the previous image-to-image feature from V1 with brand-new possibilities for creative applications. Depth2img infers the depth of an input image (using an existing model) and then generates new images using both the text and depth information.

The input image (left) can produce several new images (right). This new model can be used for structure-preserving image-to-image and shape-conditional image synthesis.
Depth-to-Image can offer all sorts of new creative applications, delivering transformations that look radically different from the original but which still preserve the coherence and depth of that image:

Depth-to-Image preserves coherence.
Updated Inpainting Diffusion Model
We also include a new text-guided inpainting model, fine-tuned on the new Stable Diffusion 2.0 base text-to-image, which makes it super easy to switch out parts of an image intelligently and quickly.

The updated inpainting model fine-tuned on Stable Diffusion 2.0 text-to-image model.
Just like the first iteration of Stable Diffusion, we’ve worked hard to optimize the model to run on a single GPU–we wanted to make it accessible to as many people as possible from the very start. We’ve already seen that when millions of people get their hands on these models, they collectively create truly amazing things. This is the power of open source: tapping the vast potential of millions of talented people who might not have the resources to train a state-of-the-art model but who have the ability to do something incredible with one.
This new release, along with its powerful new features like depth2img and higher resolution upscaling capabilities, will serve as the foundation of countless applications and enable an explosion of new creative potential.

For more details about accessing the model, please check out the release notes on our GitHub: https://github.com/Stability-AI/StableDiffusion
We will offer active support to this repository as our direct contribution to open source AI and look forward to all the amazing things you all build on it.
We are releasing these models into the Stability AI API Platform (platform.stability.ai) and DreamStudio in the next few days. We will send an update with information for developers and partners, including pricing updates. We hope you all enjoy these updates!
We are hiring researchers and engineers who are excited to work on the next generation of open source Generative AI models! If you’re interested in joining Stability AI, please contact careers@stability.ai, with your CV and a short statement about yourself.